


На протяжении многих лет исследователи в области искусственного интеллекта (ИИ) мечтали о разработке инструментов, которые могли бы ускорить развитие науки, ставя перед учеными новые вопросы, разрабатывая эксперименты и, возможно, даже проводя их. В последние месяцы большие языковые модели (БЯМ) сделали открытия, которые, по мнению некоторых разработчиков ИИ, приближают нас к этому будущему. Но как проверить, действительно ли ИИ может заниматься наукой?
В поисках ответов исследователи обращаются к контрольным показателям: стандартизированным наборам вопросов или задач, которые помогают оценить возможности ИИ и сравнить его с другими моделями. Но из-за сложности науки оценить способность ИИ к обучению особенно непросто. Как выразился Хао Пэн, специалист по информатике из Иллинойсского университета в Урбане-Шампейне: «У моделей есть все эти знания. Но умеют ли они ими пользоваться?»
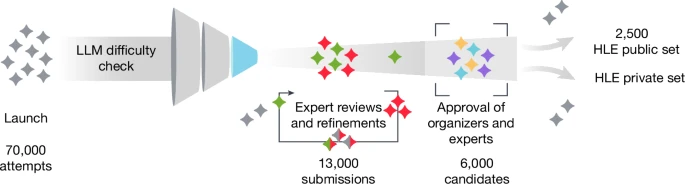
За последний год появилось множество новых научно обоснованных критериев для ответа на этот вопрос, но ученым еще предстоит выбрать наиболее оптимальный подход. Один из самых популярных критериев, опубликованный в Nature в прошлом месяце, — это «Последний экзамен человечества» (Humanity’s Last Exam, HLE).

Распределение вопросов по областям знания.
Он включает 2500 вопросов из области «передовых человеческих знаний», которые позволяют проверить большие языковые модели на прочность. Например, один из вопросов касается того, сколько парных сухожилий поддерживает сесамовидная кость колибри.
«Нам нужен был разнообразный набор данных, на который могли бы ответить только эксперты, давно работающие в этой области», — говорит Лонг Фан, инженер-исследователь из некоммерческой организации Center for AI Safety, разработавшей HLE.
С тех пор как в январе 2025 года HLE впервые был представлен в виде препринта, этот бенчмарк стал важной площадкой для тестирования больших языковых моделей. Показатели HLE теперь часто упоминаются компаниями, занимающимися разработкой ИИ, которые стремятся продемонстрировать возможности своих продуктов.
На момент запуска HLE модель o1 от известного разработчика OpenAI набрала наибольшее количество баллов — всего 8,3%. Ранее в этом месяце компания Google похвасталась, что ее новейшая научная модель рассуждений под названием Gemini 3 Deep Think достигла нового рекордного показателя HLE — 48,4 %.
Однако некоторые ученые утверждают, что многие вопросы HLE проверяют наличие узкоспециализированных — и даже тривиальных — знаний, а не способность проводить значимые исследования. «Как знание о том, сколько в мире существует аллотропных модификаций фосфора, поможет в научных открытиях?» — спрашивает Ченру Дуан, основатель компании Deep Principle, занимающейся разработкой искусственного интеллекта для науки.
В Nature редакционной статье, сопровождавшей публикацию HLE, эта обеспокоенность нашла отражение: «Мы считаем, что многим ученым стоит задаться вопросом: что нужно сделать, чтобы разработать эталонный тест для ИИ, который действительно оценивал бы мышление на уровне эксперта?»

По словам исследователей из OpenAI, у них есть новый ориентир, который движется в этом направлении. Выпущенный в декабре 2025 года тест FrontierScience предназначен для выявления «научных рассуждений на уровне эксперта» с помощью 700 вопросов по химии, биологии и физике.
Некоторые из них похожи на вопросы, которые используются на олимпиадах по математике и естественным наукам. Они часто основаны на кратком сценарии, имеют однозначный ответ и, по словам научного сотрудника OpenAI Майлза Ванга, являются «достойным показателем чисто интеллектуальных усилий».
Один из примеров: определение продуктов, образующихся в результате ряда химических реакций. Другие вопросы основаны на сложных, открытых исследовательских задачах, подобных тем, над которыми работают аспиранты, например о том, как изменение определенной молекулы может повлиять на ее свойства.
По словам Вана, главное преимущество этого бенчмарка — проверяемость, одна из важнейших характеристик объективного теста. Вопросы олимпиады легко поддаются оценке, а за ответы на открытые исследовательские вопросы большие языковые модели получают баллы за выявление промежуточных логических шагов.
На данный момент лучший результат в FrontierScience показал собственный продукт OpenAI — GPT-5.2, который правильно ответил на 77% вопросов олимпиады и набрал 25% баллов за исследовательские задачи.
Другие исследователи считают, что такой большой разрыв в результатах говорит сам за себя. Они утверждают, что при сравнительном анализе следует ориентироваться на непосредственную оценку способности ИИ проводить реальные исследования.
Это основополагающий принцип бенчмарка под названием Scientific Discovery Evaluation (SDE), который Дуан и его коллеги опубликовали на той же неделе, что и FrontierScience.
Вместо того чтобы задавать сложные, но не связанные между собой вопросы, SDE предлагает ИИ 1125 задач, связанных с 43 исследовательскими сценариями, из восьми текущих реальных исследовательских проектов с еще не опубликованными данными.
Например, LLM предлагается выяснить, как разложить целевую молекулу на более простые, коммерчески доступные ингредиенты. Модели оцениваются не только по отдельным ответам, но и по их способности собирать воедино целые проекты — выдвигать, тестировать и корректировать гипотезы на протяжении нескольких этапов. «Мы гарантируем, что ответ на каждый вопрос связан с небольшим реальным научным открытием», — говорит Дуан.
Результаты SDE показали, что способность больших языковых моделей правильно отвечать на отдельные вопросы не всегда гарантирует высокую эффективность при работе над полноценными проектами, и наоборот.
«Часто важнее знать общую картину, чем точные свойства определенных молекул», — говорит Дуан. Кроме того, бенчмарк показал, что лучшие модели от разных разработчиков, в том числе от OpenAI, Anthropic, xAI и DeepSeek, часто застревают на одних и тех же самых сложных вопросах. Эта закономерность указывает на то, что они могут сталкиваться с одними и теми же ограничениями, вероятно, потому, что обучаются на схожих массивах научных данных.
Однако даже подход SDE охватывает лишь часть научного процесса. Еще один новый бенчмарк, ориентированный на биологию, LABBench2 от стартапа FutureHouse, занимающегося разработкой искусственного интеллекта для науки, призван проверить, способны ли ученые, использующие ИИ, довести проект от первоначальной идеи до публикации.
Этот бенчмарк, выпущенный в этом месяце, включает почти 1900 задач, которые позволяют оценить, насколько хорошо так называемые агентные модели ИИ — системы, которые действуют независимо для выполнения многоэтапных задач, — справляются с такими задачами, как поиск литературы, доступ к данным и составление последовательностей генов.
Пока что результаты неоднозначны. Многие ведущие языковые модели хорошо справляются с поиском по полнотекстовым патентам и лабораторным исследованиям. Но они часто не справляются с более сложными задачами LABBench2, такими как перекрестные ссылки на несколько баз данных, поиск и интерпретация конкретных рисунков или данных в объемных научных статьях.
По словам Джона Лорана из Edison Scientific, коммерческого подразделения FutureHouse, прогресс в создании настоящего ученого-исследователя на основе искусственного интеллекта будет отчасти зависеть от улучшения способов извлечения информации и навигации в ней.
По словам исследователей, важно понимать, что эталонные показатели нужны не только для того, чтобы понять, кто сейчас лидирует. Более строгие эталонные показатели также могут стимулировать инновации, ставя новые цели перед большими языковыми моделями и другими инструментами искусственного интеллекта. «Одна из целей эталонных показателей — опережать время, измерять потенциальные возможности и стимулировать их развитие», — говорит Лоран.
«Для большинства прорывных открытий когда-то существовал эталон, который служил путеводной звездой в этой области», — соглашается Ван. По его словам, одним из самых известных примеров стал конкурс ImageNet Large Scale Visual Recognition Challenge, в рамках которого компьютерам предлагалось распознавать изображения. Победителем конкурса 2012 года стала нейросеть AlexNet, которая дала толчок развитию сверточных нейронных сетей — основы современного искусственного интеллекта.
Во многих областях не существует единого критерия, по которому можно было бы судить о том, насколько ИИ «хорош» в науке. «Именно поэтому мы наблюдаем такую неоднородность в используемых критериях, — говорит Анна Иванова, изучающая когнитивную нейробиологию и искусственный интеллект в Технологическом институте Джорджии. — То, насколько хорошо система отображает ваши данные, сильно отличается от ее фактических знаний в области аналитической химии, хотя ученому могут быть нужны и те, и другие».

Учитывая разнообразие навыков, необходимых для работы в науке, специалисты по искусственному интеллекту считают, что исследовательскому сообществу лучше всего опираться на целый набор тестов, каждый из которых направлен на улучшение той или иной части научного процесса. «Мы движемся к миру, в котором нам понадобится более разнообразный набор методов оценки», — говорит Ван.
Какой бы подход вы ни выбрали, то, что поддается измерению, скорее всего, станет ориентиром для улучшений. «Чтобы добиться прогресса, — говорит Пэн, — нужно уметь его измерять».
Источник: Science